


東京大学大学院工学系研究科 教授 浅見泰司先生インタビュー「空間関係・統計的性質を保持しつつ空間的個体特定化危険を回避するための空間情報安全化処理方法の開発」(第1回)
年収にあたる被説明変数だけではなく、住所や年齢などの説明変数にノイズを入れることはできないのでしょうか。
説明変数にノイズを付加して疑似データを作成する方法はあります。被説明変数はひとつだけですが、説明変数は複数あるため、より自由に幅広く、疑似データを作成することができます。ただしノイズの幅が増えると、分析結果も曖昧なものになってしまいます。いずれにしても、説明変数にノイズを付加して疑似データを作成する方法は引き続き研究中です。
さて、目的変数にノイズを付加する話に戻しますと、データにノイズを与えるとき、その攪乱の程度を操作するパラメータがあります。目的変数に攪乱を与える方法は、理論の上では確認できていたのですが、説明変数の中にさまざまな相関が潜んでいることから、どの程度のパラメータの値が適切であるかは、不動産データを用いて実際に検証するしかありませんでした。
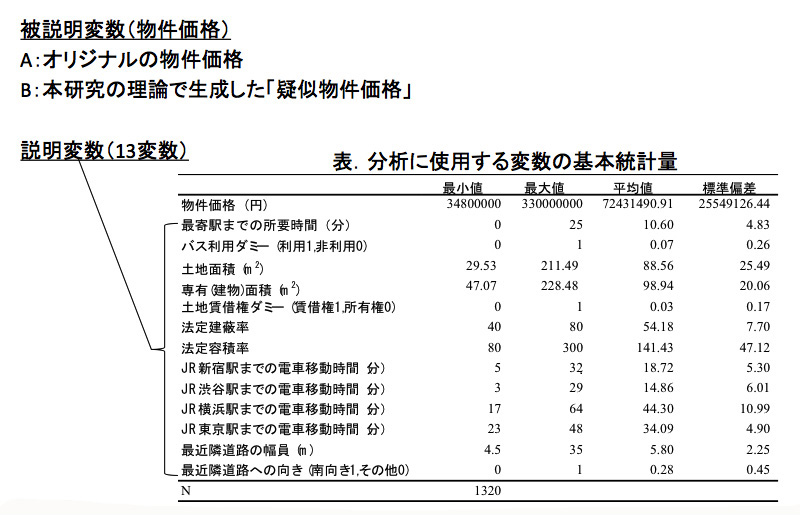
使用したのは、ある不動産情報サービス会社の不動産取引データ1320件に、都内主要駅までの移動時間や最近隣道路の幅員など、13の説明変数を加えたものです。これをもとに、本件研究の理論で「疑似物件価格」を生成しました。
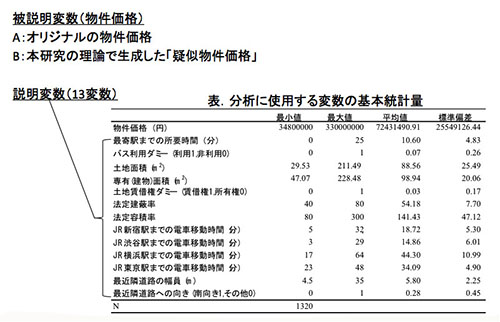
次に「オリジナルの物件価格」と「疑似物件価格」のデータのばらつきを確かめるため、ボックスプロット図を作成しました。図の左端がオリジナルの物件価格データであり、それ以外の4つは疑似物件価格データです。
上下の短い横線はデータの最大値と最小値、中央付近の四角い箱はデータの50%を占める中間層、中心の線は「そのデータを代表する最も一般的なデータ」を示しています。
さて、目的変数にノイズを付加する話に戻しますと、データにノイズを与えるとき、その攪乱の程度を操作するパラメータがあります。目的変数に攪乱を与える方法は、理論の上では確認できていたのですが、説明変数の中にさまざまな相関が潜んでいることから、どの程度のパラメータの値が適切であるかは、不動産データを用いて実際に検証するしかありませんでした。
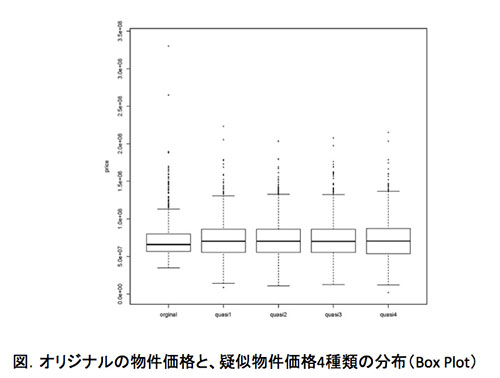
使用したのは、ある不動産情報サービス会社の不動産取引データ1320件に、都内主要駅までの移動時間や最近隣道路の幅員など、13の説明変数を加えたものです。これをもとに、本件研究の理論で「疑似物件価格」を生成しました。
次に「オリジナルの物件価格」と「疑似物件価格」のデータのばらつきを確かめるため、ボックスプロット図を作成しました。図の左端がオリジナルの物件価格データであり、それ以外の4つは疑似物件価格データです。
上下の短い横線はデータの最大値と最小値、中央付近の四角い箱はデータの50%を占める中間層、中心の線は「そのデータを代表する最も一般的なデータ」を示しています。
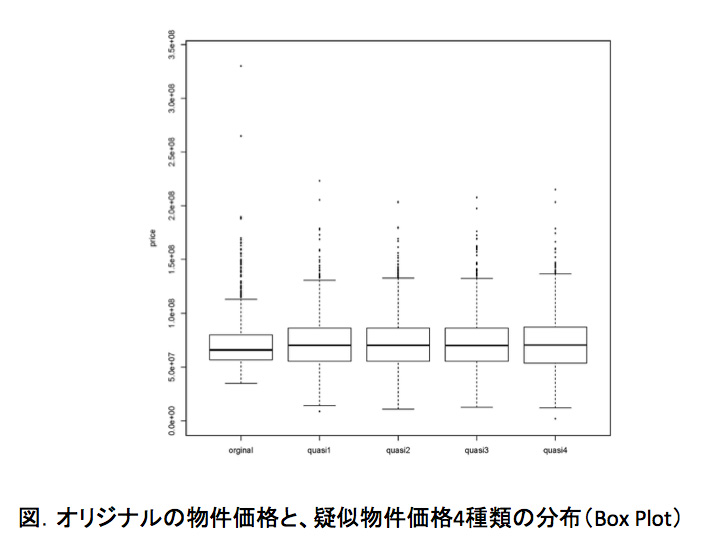
オリジナルデータと比べて、4つの疑似データは最小値と最大値の幅が広がっていますが、中心線はあまり変わらないのですね。中間層のデータは同じくらい、ということでしょうか。
そうでもありません。オリジナルの物件価格と4つの疑似物件価格の散布図を作成したところ、次のような結果になりました。2つのデータがほぼ同じ数値であれば一直線になるのですが、かなり分散していることがわかります。
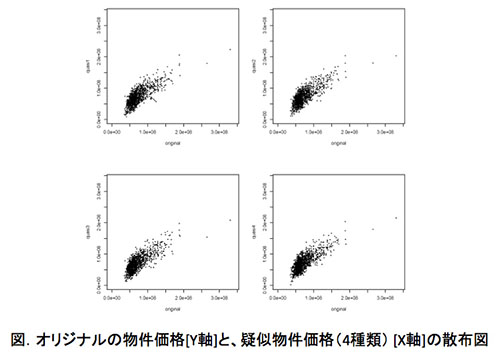
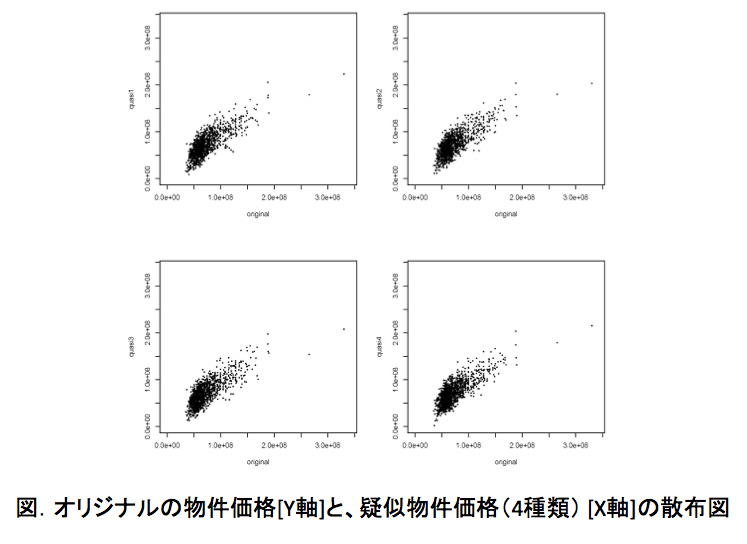
オリジナルデータと疑似データは、だいぶ数値が違うのですね。これだけ差があっても分析結果がほぼ同じになるというのは、すごいことだと思います。
注意しなければならないのは「疑似データの決定係数R2とt値がオリジナルデータと一致する」といえるのは「全データを使用した場合」のみであることです。実際、分析者が不動産データを扱うとき、数百・数千ものデータをすべて使用するわけではありません。「賃貸住宅のみ」「南向きの物件のみ」「東京駅まで30分以内の物件のみ」というふうに、データの一部を抽出して使用することが多々あります。
この研究で作成した疑似データ1320件すべてを使用した場合は、R2とt値がオリジナルデータと一致します。しかし20%(264件)のデータを抽出して分析した場合、この数値は変わってしまいます。つまりオリジナルデータで分析した場合と同じ結果になるとは限らないのです。
この研究で作成した疑似データ1320件すべてを使用した場合は、R2とt値がオリジナルデータと一致します。しかし20%(264件)のデータを抽出して分析した場合、この数値は変わってしまいます。つまりオリジナルデータで分析した場合と同じ結果になるとは限らないのです。
疑似データのうち10%や20%しか使わなかったとしても、やはり一定の品質保証が求められるということですか。
そうです。この研究では「オリジナルデータで分析した結果とほぼ変わらないと言える、分析者にとって十分満足できる誤差の範囲」を95%としました。
その上で「オリジナル物件価格の重回帰モデル」と「オリジナル物件価格と疑似物件価格の重回帰モデル」の2モデルが同じになるかどうか、さまざまな抽出率とパラメータの値を組み合わせて、その組み合わせ毎に1000回計算を行いました。
結果、パラメータの値が1のときに、10%という少ない抽出率でも95%近い確率で回帰係数の一致がみられることを確認しました。

その上で「オリジナル物件価格の重回帰モデル」と「オリジナル物件価格と疑似物件価格の重回帰モデル」の2モデルが同じになるかどうか、さまざまな抽出率とパラメータの値を組み合わせて、その組み合わせ毎に1000回計算を行いました。
結果、パラメータの値が1のときに、10%という少ない抽出率でも95%近い確率で回帰係数の一致がみられることを確認しました。

この研究の中で、一番の驚きや発見は何でしたか。
正直に言うと、ここまで上手く理論的に構築できるとは思っていませんでした。
たとえばデータにノイズを加えるという方法は、他にもたくさんあります。小さなノイズであれば、ランダムに加えてもある程度の精度を得ることができます。しかしR2とt値がオリジナルデータと一致することはありません。もちろん「オリジナルデータで分析した場合と同じ結果を出す、疑似データの作成方法があるはずだ」と思ってこの研究を始めましたが、実際にやってみて「ここまでできるのか」というのが、一番の驚きでした。世界に先駆けて新しい理論を生み出すことができたことが、驚きと同時に喜びでもあります。
たとえばデータにノイズを加えるという方法は、他にもたくさんあります。小さなノイズであれば、ランダムに加えてもある程度の精度を得ることができます。しかしR2とt値がオリジナルデータと一致することはありません。もちろん「オリジナルデータで分析した場合と同じ結果を出す、疑似データの作成方法があるはずだ」と思ってこの研究を始めましたが、実際にやってみて「ここまでできるのか」というのが、一番の驚きでした。世界に先駆けて新しい理論を生み出すことができたことが、驚きと同時に喜びでもあります。
今年も7月から、平成27年度の研究助成申請がスタートしました。これから申請する若手の研究者に対してメッセージがありましたら、お願いします。
 失敗を恐れず、少し挑戦的なテーマにチャレンジしてもらいたいですね。それは必ず良い経験になります。手堅い研究は面白くありませんし、最初から「できる」と分かっているテーマに取り組むことは「研究」ではありません。
失敗を恐れず、少し挑戦的なテーマにチャレンジしてもらいたいですね。それは必ず良い経験になります。手堅い研究は面白くありませんし、最初から「できる」と分かっているテーマに取り組むことは「研究」ではありません。一般的な研究助成では、研究費の使い道について厳しい規制がありますが、セコムさんは研究費の使い方に対しても寛容なので、今まで諦めていたこと、面白いことや新しいことに、ぜひ挑戦してみてください。