


東京大学大学院工学系研究科 教授 浅見泰司先生インタビュー「空間関係・統計的性質を保持しつつ空間的個体特定化危険を回避するための空間情報安全化処理方法の開発」(第2回)
空間情報とは「場所」を明示したデータのことです。そこには位置情報と属性情報が含まれており、個人の特定に繋がるリスクがあります。しかし情報化が進んだ現代社会では、そうしたビッグデータは企業ビジネスや政策立案に不可欠なものになりました。
東京大学大学院工学系研究科の浅見教授は、ビックデータに含まれるプライバシーを守りながら、そのデータを社会で有効活用する手法についてご研究されています。2回目のインタビューでは、情報が収集段階から秘匿され、かつ秘匿されたまま活用される方法についてお伺いします。
「助成研究者個人ページへ」

1982年3月東京大学工学部都市工学科卒業。1984年3月同大学の大学院工学系研究科都市工学専攻修士課程修了。その後ペンシルバニア大学に留学し、地域科学専攻博士課程を修了。帰国後は東京大学に戻り、2001年4月に同大学空間情報科学研究センターの教授となる。副センター長からセンター長を務めた後、2012年8月東京大学大学院工学系研究科都市工学専攻教授に就任し、現在に至る。
前回は、空間情報にノイズを加えることでデータを曖昧化させながらも、データ解析を行う上で重要な指標となる数値は変えない疑似データの作成方法について教えていただきました。今回の「センシングした空間情報を取得した時点の空間情報の安全化手法」は、どのような違いがあるのでしょう。
前回は収集したデータを曖昧化させる方法でしたが、今回はデータ収集時のプライバシー保護、およびデータを暗号化したまま活用する方法です。
この研究では2つの目的がありました。ひとつは「スマートフォンを用いたユーザ参加型センシングにおけるデータ収集とプライバシー保護」(瀬崎薫教授が中心になって研究)、もうひとつは「秘密分散を用いた秘匿演算方式の開発」(岩村恵市教授が中心になって研究)です。まずは前者のほうから説明します。
ユーザ参加型センシングとは、スマートフォン等の携帯端末から空間データをセンシングする手法です。スマートフォンの普及率と、端末に搭載されているセンサの高機能化・多様化から、参加型センシングによって従来よりも高い時空間密度における空間データの取得が期待できます。
この研究では2つの目的がありました。ひとつは「スマートフォンを用いたユーザ参加型センシングにおけるデータ収集とプライバシー保護」(瀬崎薫教授が中心になって研究)、もうひとつは「秘密分散を用いた秘匿演算方式の開発」(岩村恵市教授が中心になって研究)です。まずは前者のほうから説明します。
ユーザ参加型センシングとは、スマートフォン等の携帯端末から空間データをセンシングする手法です。スマートフォンの普及率と、端末に搭載されているセンサの高機能化・多様化から、参加型センシングによって従来よりも高い時空間密度における空間データの取得が期待できます。
スマートフォンにはユーザの現在位置を示すGPSが搭載されていますし、本人の電話番号やメールアドレス、住所、年齢、ネットショップでの購入履歴など、多くの個人情報が入っていますが、そうした情報をユーザが自ら提供するのは難しい気がします。
情報をそのまま提供すると個人情報漏洩のリスクが高まるため、プライバシー保護は必須です。そうした情報提供者のプライバシーを守りながら空間情報を集める方法のひとつに、Negative Surveyがあります。
たとえば選挙があると、テレビ局や新聞社は出口調査を行います。このとき「あなたはどの候補者に投票しましたか?」と質問しますが、投票した人にとって、これはあまり答えたくない内容です。
報道機関が知りたいのは「その人が誰に投票したのか」ではなく「各候補者がどれだけ票を得たのか」です。つまり「誰に投票したか言わせなくても、各候補者の得票率を導き出せる方法」があれば良いのです。
たとえば選挙があると、テレビ局や新聞社は出口調査を行います。このとき「あなたはどの候補者に投票しましたか?」と質問しますが、投票した人にとって、これはあまり答えたくない内容です。
報道機関が知りたいのは「その人が誰に投票したのか」ではなく「各候補者がどれだけ票を得たのか」です。つまり「誰に投票したか言わせなくても、各候補者の得票率を導き出せる方法」があれば良いのです。
別の質問をして、その答えから各候補者の得票率を算出するということでしょうか。
そうです。たとえば投票した人が答えやすいように、質問内容を「投票しなかった候補者を1人選んでください」とします。「投票しなかった候補者」のデータが一定数集まり、ある計算を行えば、各候補者の得票率が分かるのです。
「投票しなかった候補者」は複数人数なので、その中からランダムに1人を選ぶことになりますが……
ランダムであるということは「確率が等しい」ということです。
これは共同研究者である瀬崎薫先生が行った研究ですが、たとえば東京都知事選で、舛添要一・宇都宮健児・細川護熙・田母神俊雄・瀬崎薫の5氏が立候補したとします。選挙の結果、各候補者の得票率は、舛添氏60%・宇都宮氏24%・細川氏12%・田母神氏4%・瀬崎氏0%でした。
この選挙の投票日に出口調査を行い、100人に対して「投票していない候補者を1人教えてください」と尋ねたとします。100人のうち、舛添氏を選んだ人は60人です。その60人の人は、宇都宮氏、細川氏、田母神氏、瀬崎氏の4人のうち誰かを選びますが、誰が選ばれるかは同じ確率です。
これは共同研究者である瀬崎薫先生が行った研究ですが、たとえば東京都知事選で、舛添要一・宇都宮健児・細川護熙・田母神俊雄・瀬崎薫の5氏が立候補したとします。選挙の結果、各候補者の得票率は、舛添氏60%・宇都宮氏24%・細川氏12%・田母神氏4%・瀬崎氏0%でした。
この選挙の投票日に出口調査を行い、100人に対して「投票していない候補者を1人教えてください」と尋ねたとします。100人のうち、舛添氏を選んだ人は60人です。その60人の人は、宇都宮氏、細川氏、田母神氏、瀬崎氏の4人のうち誰かを選びますが、誰が選ばれるかは同じ確率です。
60人の投票者が4人の候補者を同じ確率で選ぶとしたら……60÷4=15ですから、各候補者は15人の投票者に選ばれるということですか。
正解です。同じように、宇都宮氏の得票率は24%ですから、宇都宮氏を選んだ24人の回答は「舛添氏」6人、「細川氏」6人、「田母神氏」6人、「瀬崎氏」6人になります。最終的には下図のような結果になるはずです。
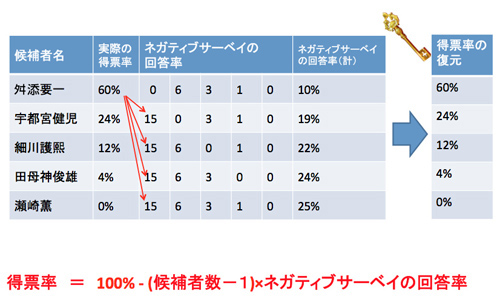
100人の投票者に「投票していない候補者」を尋ねた結果、舛添氏10%、宇都宮氏19%、細川氏22%、田母神氏24%、瀬崎氏25%という回答率になりました。
この状態では意味のない数字に見えますが、
〔1〕「全候補者数マイナス1」にNegative Surveyの回答率を乗算する。
〔2〕100%から〔1〕の値を引く。
この手順で計算をすると、実際の得票率が復元されます。
たとえば舛添氏のNegative Survey回答率は10%なので、
〔1〕(5-1)×10%=40%
〔2〕100%―40%=60%
このように、得票率が算出できるのです。
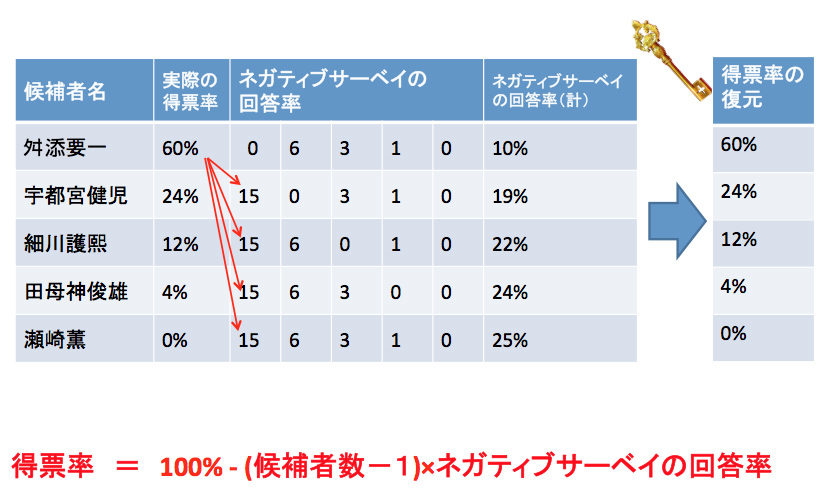
100人の投票者に「投票していない候補者」を尋ねた結果、舛添氏10%、宇都宮氏19%、細川氏22%、田母神氏24%、瀬崎氏25%という回答率になりました。
この状態では意味のない数字に見えますが、
〔1〕「全候補者数マイナス1」にNegative Surveyの回答率を乗算する。
〔2〕100%から〔1〕の値を引く。
この手順で計算をすると、実際の得票率が復元されます。
たとえば舛添氏のNegative Survey回答率は10%なので、
〔1〕(5-1)×10%=40%
〔2〕100%―40%=60%
このように、得票率が算出できるのです。
「誰に投票したか」を答えていないのに、質問を変えて簡単な計算をすれば、各候補者の得票率が分かるというのは、すごいですね。
この方法は、選ぶ相手が3人以上いる場合に成立します。たとえば「AさんとBさん、どちらを選ぶ?」という質問を「AさんとBさん、選ばないのはどっち?」に変えても、回答者が選んだ相手は調査者にばれてしまいます。しかし「Aさん・Bさん・Cさんから1人を選んで、選ばなかった人を1人だけ教えてください」という質問であれば、「Cさん」と答えた人のデータを見ても、その人がAさん・Bさんのどちらを選んだのかは曖昧なままです。
このように、対象が3つ以上ある場合はNegative Surveyを使うことで「本当の答え」が分からなくても、数式処理によって「本当の答え」を統計的に復元することができます。
ただし、扱うデータが離散データや1次元データなら良いのですが、連続データや多次元データの分析には、Negative Surveyは不向きです。
このように、対象が3つ以上ある場合はNegative Surveyを使うことで「本当の答え」が分からなくても、数式処理によって「本当の答え」を統計的に復元することができます。
ただし、扱うデータが離散データや1次元データなら良いのですが、連続データや多次元データの分析には、Negative Surveyは不向きです。