


東京大学大学院工学系研究科 教授 浅見泰司先生インタビュー「空間関係・統計的性質を保持しつつ空間的個体特定化危険を回避するための空間情報安全化処理方法の開発」(第1回)
それでは先生が携わった「収集された空間情報に対してノイズ付加による空間情報安全化処理手法研究」から、詳しく教えていただけますか。
これは、丸山先生、刀根先生と取り組んだ研究で、特に、理論面は丸山先生の貢献がとても大きいものです。
たとえば個人情報のなかでも「年収」というのはとてもセンシティブなデータですが、その他の「男性」「東京都在住」等の情報は開示されても構わないとします。それならば「年収」にある数字を足したり引いたりしてノイズを加えた疑似データを作成すれば、データを受け取った相手に正確な年収が伝わることはありません。
たとえば個人情報のなかでも「年収」というのはとてもセンシティブなデータですが、その他の「男性」「東京都在住」等の情報は開示されても構わないとします。それならば「年収」にある数字を足したり引いたりしてノイズを加えた疑似データを作成すれば、データを受け取った相手に正確な年収が伝わることはありません。
ノイズが加えられた疑似データは正確なデータではありませんから、そこから得られる分析も正確なものではない、ということになりそうですが……。
実は「データの値が変わっても正確な分析結果を出す方法」があるのです。まずは回帰分析と呼ばれる方法について説明します。
回帰分析のなかでも経済学の分野でよく使用されているのが「商品の価格は、その性能や機能が持つ価値の集合体である」という考え方に基づいたヘドニック回帰です。
たとえば不動産の価格は、物件価格や土地面積、最寄り駅までの所要時間や近隣道路に対する向きなどによって、大きく変動します。価格の原因となるそれらの変数を「説明変数」としてxで表し、さまざまな要素が影響した結果として出された価格の変数を「被説明変数」としてyで表したとき、不動産価格は次のような式で表現できます。
不動産の価格y = b0+b1x1+b2x2+b3x3+……+bmxm
回帰分析のなかでも経済学の分野でよく使用されているのが「商品の価格は、その性能や機能が持つ価値の集合体である」という考え方に基づいたヘドニック回帰です。
たとえば不動産の価格は、物件価格や土地面積、最寄り駅までの所要時間や近隣道路に対する向きなどによって、大きく変動します。価格の原因となるそれらの変数を「説明変数」としてxで表し、さまざまな要素が影響した結果として出された価格の変数を「被説明変数」としてyで表したとき、不動産価格は次のような式で表現できます。
不動産の価格y = b0+b1x1+b2x2+b3x3+……+bmxm
yとxは分かるのですが、bは何を表しているのですか。
たとえば「南向き」と「西向き」の2つの物件があり、土地面積や最寄り駅までの距離などの条件がすべて同じであるにも関わらず「南向き」物件の方が50万円高いとします。調べてみると「南向き」物件はバルコニーに差し込む日照時間が「西向き」物件よりも1時間長かったため「日照時間1時間あたり50万円の価値がある」と分析できます。
このとき、日照時間を「価格を決定する説明変数のひとつ」としてx1と表したとき、「日照時間1時間ごとの価値」がb1になります。同様に、最寄り駅までの距離をx2とすると、最寄り駅までの距離の長さによって生み出される価値はb2となります。通常は駅から遠いほど不便なので、b2は負になることが想定されます。b0は説明変数の値がすべて0であったときの価値です。
このとき、日照時間を「価格を決定する説明変数のひとつ」としてx1と表したとき、「日照時間1時間ごとの価値」がb1になります。同様に、最寄り駅までの距離をx2とすると、最寄り駅までの距離の長さによって生み出される価値はb2となります。通常は駅から遠いほど不便なので、b2は負になることが想定されます。b0は説明変数の値がすべて0であったときの価値です。
つまり戸建て住宅に住んでいる人にとって、目の前にマンションが建設されて日照時間が減ってしまったら、b1×x1の数値分だけ家の価値が減少することになるのですね。
マンション建設によって5戸の住宅の日照時間が1時間ずつ減るとしたら、それは「地域住民に対して250万円の損害を与える」ことになります。つまり「マンション建設が地域社会に対して250万円以上の価値を生み出す」という明確な根拠がない限り、社会的に考えれば「マンション建設を認めるべきではない」という結論になります。
このようにヘドニック回帰を用いた分析は「その事業が社会にとってプラスになるのか、マイナスになるのか」という判定を可能にします。国や自治体の政策はもちろん、企業の新事業を分析する手法としても有効です。
このようにヘドニック回帰を用いた分析は「その事業が社会にとってプラスになるのか、マイナスになるのか」という判定を可能にします。国や自治体の政策はもちろん、企業の新事業を分析する手法としても有効です。
政策や事業が社会にもたらすプラス効果やマイナスの影響が数値で明確に表せるということに、とても驚きました。では、それらの情報にノイズを加えた「疑似データ」の作り方について教えていただけますか。
個人情報が含まれたデータを分析者に提供するときは、オリジナルデータをそのまま渡すのではなく、ノイズを加えた疑似データの提供が望ましいといえます。もちろん分析者は現実に即した正しい分析結果を求めるため、疑似データには「オリジナルデータを用いた場合とほぼ同じ分析結果が得られる」という品質保証が必要です。
そのためには回帰分析において重要な決定係数R2やt値が、オリジナルデータと同一でなければなりません。
そのためには回帰分析において重要な決定係数R2やt値が、オリジナルデータと同一でなければなりません。
「決定係数R2」と「t値」は、何を表わす数値ですか?
回帰分析とは、説明変数xの値から、被説明変数つまり目的変数であるyの値を予測するための手法であり、分析結果は回帰式という数式で表されます。
決定係数R2は、この回帰式がどれだけ現実とフィットしているかを示すものです。R2値が大きいときは回帰式の予想値と現実の値の誤差が小さいため、現実にフィットした状態といえます。一方R2値が小さいときは予想値と現実の値との誤差が大きいため、現実と乖離している状態ということになります。
t値は、回帰分析における各変数の重要性を評価する値です。この値が大きいほど、それぞれの説明変数が被説明変数に与える影響が強いということであり、統計的に有意であるといえます。
解析者が回帰分析を行うとき、決定係数R2とt値は、最も関心を寄せる指標です。このため疑似データのR2とt値は、オリジナルデータと同一でなければなりません。
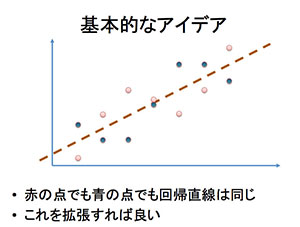 基本的な考え方は、左図のようになります。縦軸がyで、横軸がxです。
基本的な考え方は、左図のようになります。縦軸がyで、横軸がxです。
赤い点が実際のデータの数値(観測値)で、直線が回帰式です。変数xから変数yを予測する際、実際の観測値との誤差が最も小さくなるのがy = a+bxです。
疑似データを作成するということは、この回帰式と全く同じ回帰式が導き出される別の観測値を作ることです。
決定係数R2は、この回帰式がどれだけ現実とフィットしているかを示すものです。R2値が大きいときは回帰式の予想値と現実の値の誤差が小さいため、現実にフィットした状態といえます。一方R2値が小さいときは予想値と現実の値との誤差が大きいため、現実と乖離している状態ということになります。
t値は、回帰分析における各変数の重要性を評価する値です。この値が大きいほど、それぞれの説明変数が被説明変数に与える影響が強いということであり、統計的に有意であるといえます。
解析者が回帰分析を行うとき、決定係数R2とt値は、最も関心を寄せる指標です。このため疑似データのR2とt値は、オリジナルデータと同一でなければなりません。
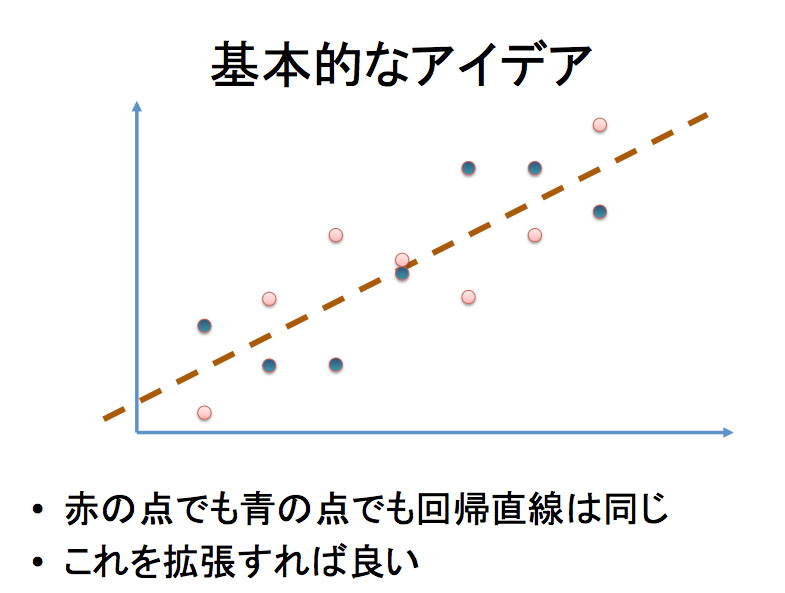 基本的な考え方は、左図のようになります。縦軸がyで、横軸がxです。
基本的な考え方は、左図のようになります。縦軸がyで、横軸がxです。赤い点が実際のデータの数値(観測値)で、直線が回帰式です。変数xから変数yを予測する際、実際の観測値との誤差が最も小さくなるのがy = a+bxです。
疑似データを作成するということは、この回帰式と全く同じ回帰式が導き出される別の観測値を作ることです。
回帰式に対して赤い点と上下対照に配置されている青い点がありますが、これが擬似的な観測点ということですか。
そうです。上下を逆にしているだけなので回帰式は同じになりますし、R2とt値も同じになります。ただし逆転させただけでは、オリジナルデータの値が簡単に分かってしまいます。そこで、このような性質を持ちながら、被説明変数にノイズを加えていくより一般的な方法を探求しました。
たとえば、Aさん「50代・東京在住・年収1000万円」、Bさん「50代・千葉在住・年収600万円」、Cさん「50代・神奈川在住・年収800万円」というデータがあり「関東圏に住む50代の平均年収は800万円」という結論が出たとします。実際はもっと多くのデータを使いますが、分かりやすくするために3人分のデータで説明します。
この場合、年齢と所在地はそのままで、Aさんの年収800万円、Bさんの年収1000万円、Cさんの年収600万円というふうに、年収の数値を入れ替えても、分析結果は同じになります。
詳しくお話しすると統計学の数式の説明になってしまうので省略しますが「被説明変数yにランダム性があるノイズを加えても、決定係数R2とt値の同一性を保証する理論」を、今回の研究で構築することができました 。
たとえば、Aさん「50代・東京在住・年収1000万円」、Bさん「50代・千葉在住・年収600万円」、Cさん「50代・神奈川在住・年収800万円」というデータがあり「関東圏に住む50代の平均年収は800万円」という結論が出たとします。実際はもっと多くのデータを使いますが、分かりやすくするために3人分のデータで説明します。
この場合、年齢と所在地はそのままで、Aさんの年収800万円、Bさんの年収1000万円、Cさんの年収600万円というふうに、年収の数値を入れ替えても、分析結果は同じになります。
詳しくお話しすると統計学の数式の説明になってしまうので省略しますが「被説明変数yにランダム性があるノイズを加えても、決定係数R2とt値の同一性を保証する理論」を、今回の研究で構築することができました 。