理化学研究所 生命医科学研究センター 総合ゲノムミクス研究チーム チームリーダー
助成期間:令和2年度〜 キーワード:マルチオミックス解析技術開発 データ駆動型科学 深層学習 研究室ホームページ
2006年3月東京大学大学院医学系研究科博士課程(病因病理学専攻)修了、医学(博士)取得。同年4月米国スタンフォード大学博士研究員となり、同大学医学部病理学課講師、リサーチアソシエートを経て、2016年10月より理化学研究所にて様々なプログラムのチームリーダー、ユニットリーダーなどを務める。2020年より生命医科学研究センター統合ゲノミクス研究チームのチームリーダーとなり、現在に至る。
いま話題のChatGPTを例に説明させてください。ChatGPTは膨大な言語データをAIに学習させ、それらの関係性や特徴を把握し、適切な配置を決定して一つの空間に押し込めています。この空間が潜在空間(特徴量空間)です。
たとえば東京の交通機関について知りたいとき、ChatGPTに「東京駅に一番近い駅はどこ?」と質問すると、おそらく「東京メトロの大手町駅」という答えが返ってくるでしょう。それは、JR東日本、新幹線、東京メトロや私鉄各社に関する情報がベースとして存在し、さらに人々が日々生成している「東京駅から東京メトロの大手町駅に徒歩で移動した」といった言語データを学習することで、AIが「この2駅は近い距離に存在している」と特徴量空間で推測できるようになったためです。
東京には複数の交通機関があるため、仮にJR東日本の全ての駅名と位置を把握できたとしても、「東京の交通機関を知っている」ことにはなりません。
「細胞X」について知りたいときは、細胞Xを構成している核と細胞質、つまり遺伝子とタンパク質の両方を調べる必要があります。対象が異なるため、2種類の測定手法(モーダル)を用いた2種類の測定データが生成されます。
この2種類のデータを適切に統合することによって、「遺伝子Aの発現が促進されたとき、タンパク質Bの生成量が増えたから、遺伝子Aとタンパク質Bは密接な関係にある」といった、複雑な情報が見えてくると期待できます。
 膨大なデータから特徴量空間を獲得する手法は言語分野に限ったものではない。医学分野でもこの技術を探求する必要があると考え、本研究を開始した
膨大なデータから特徴量空間を獲得する手法は言語分野に限ったものではない。医学分野でもこの技術を探求する必要があると考え、本研究を開始した人間が生成するデータ、たとえば遺伝子の名称は発見者の名前や、「◯◯の次に発見されたから◯◯Ⅱ」という感じで命名される傾向があります。そうした名称は本質とは無関係であり、AIにとってはわかりにくいため、学習の過程でベクトルや座標などに翻訳されていきます。
人間が作ったデータは複雑な「高次元」、AIが数学的に翻訳したデータはシンプルな「低次元」と呼ばれ、高次元のデータはAIによって低次元に変換(エンコード)されます。そしてChatGPTが質問に回答する際は、特徴量空間に存在する低次元の回答が高次元に復元(デコード)されて出力される、とお考えください。
低次元から高次元を生成する仕組みは深層生成モデルと呼ばれており、その役割は、いわば「検算」です。
たとえば野菜の味噌汁と、それをフリーズドライ化した固形物は、形状も重さも全く違います。しかし、お湯をかけて復元したとき、元の野菜の味噌汁を寸分たがわず再現できたなら、この2つはまったく同じ情報を有していることになります。
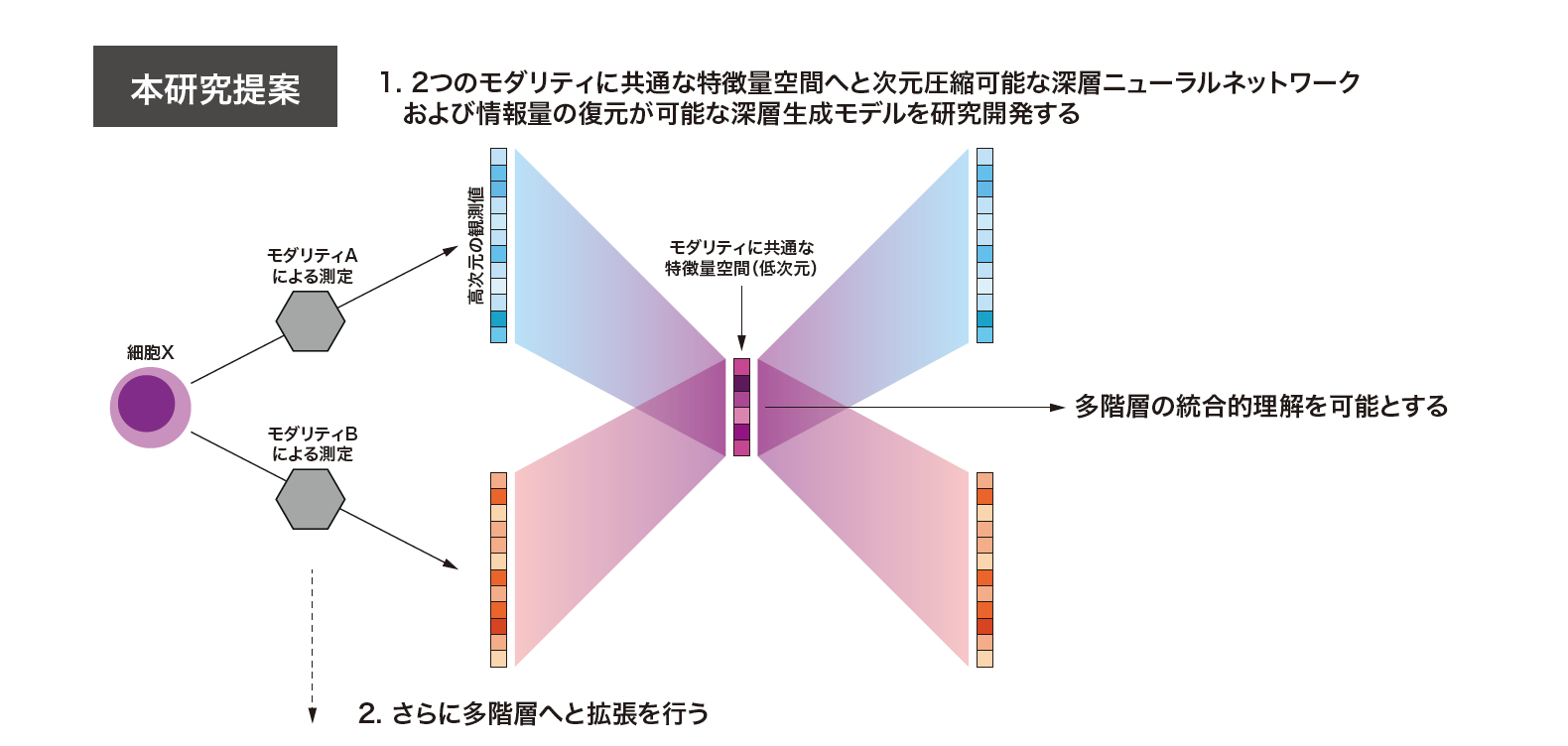 高次元から低次元に縮約する際は、多重構造のニューラルネットワークに教師データを入力し、AIが自動的に特徴を定義して学習を進めていく技術が用いられる
高次元から低次元に縮約する際は、多重構造のニューラルネットワークに教師データを入力し、AIが自動的に特徴を定義して学習を進めていく技術が用いられる