千葉工業大学 数理工学研究センター 上席研究員
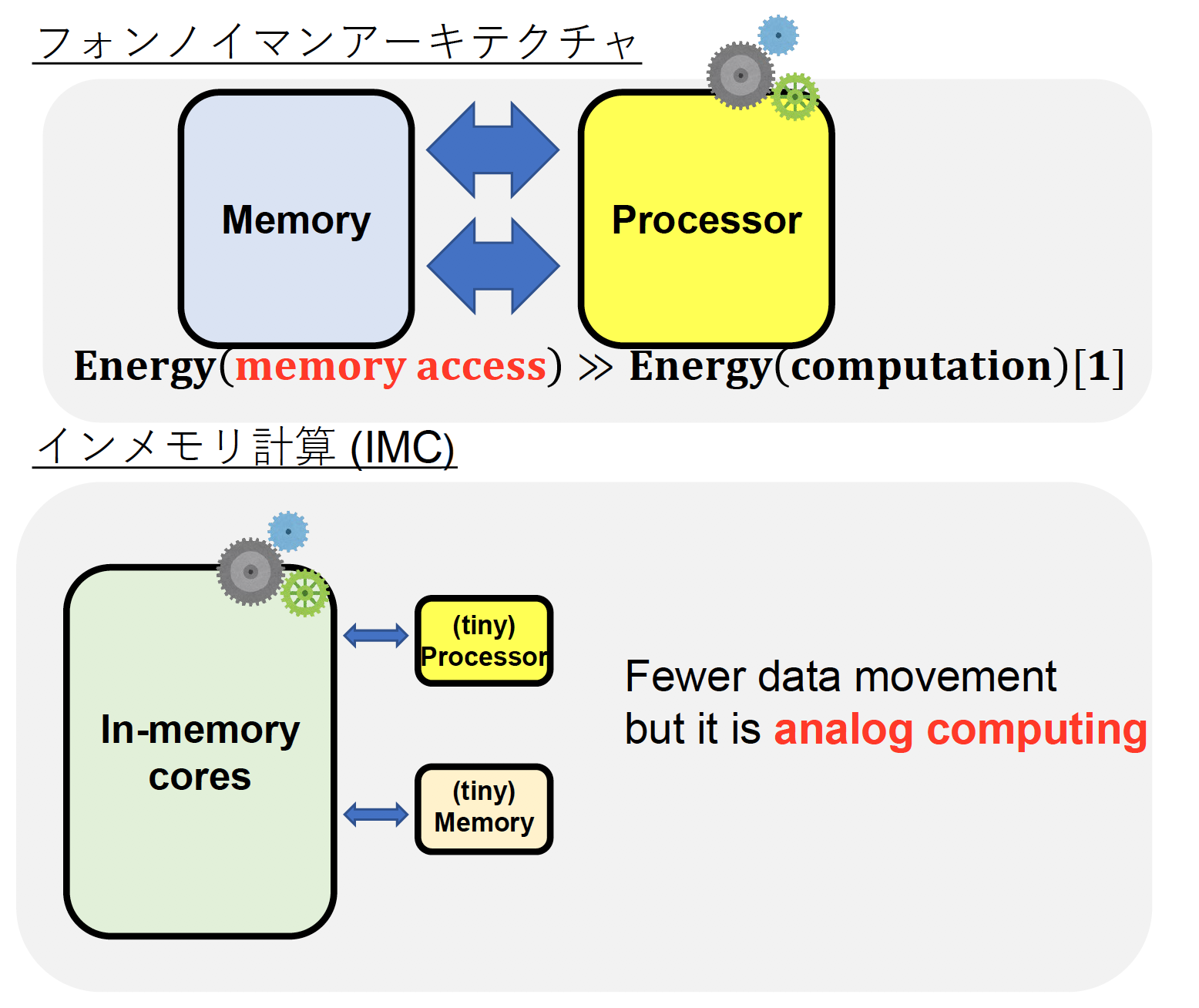
一般的な計算機は、プロセッサとメモリが独立しています。計算はプロセッサで実行され、データの保持はメモリで行われます。AIモデルもメモリに保管されています。
入力されたデータをAIが処理するときは、①「データ+モデル」をプロセッサに移動する、②プロセッサで計算を行う、③「計算結果+モデル」をメモリに移動する、これを何度も繰り返します。AIの電力消費の大部分は、この「メモリとプロセッサの間のデータ移動」によって生じているのです。
この電力のロスを解消するための方法として、私はアナログの演算回路である「インメモリ回路」に着目しました。AIモデルをハードウェアにマッピングし、プロセッサと一体化させたものです。メモリとモデルが抵抗値として回路内に存在しているため、データ移動に必要なエネルギーが不要となり、1000倍の電力効率が実現するのです。
 インメモリ回路では、抵抗に流れる電流を足し算することで、深層学習のコア演算である積和演算を行う
インメモリ回路では、抵抗に流れる電流を足し算することで、深層学習のコア演算である積和演算を行うただし、アナログ回路は大規模化が困難なため、処理できるデータ量やAIモデルの大きさが制限されます。そこで、高い予測精度を実現し、かつ大規模なハードウェア化が可能なレザバーコンピューティング(RC)に着目しました。
一般的なニューラルネットワークでは、ネットワーク全体を学習させることで入力データのパターンを認識できるようになります。特に、ネットワークを「出力を担う出力層」と「それ以外の隠れ層」に分けて考えると、隠れ層は入力パターンの特徴をうまく捉えられるように学習されます。この学習された隠れ層は、ニューラルネットワークの性能を大きく押し上げますが、ハードウェア化は困難です。隠れ層は複雑な動作をするため、それを再現するためには、精密にハードウェアを作りこむ必要があるからです。
一方、RCでは出力層のみを学習します。隠れ層を学習しないということは、作り込む必要がないと考えることができます。このため、RCはハードウェア化しやすいという特徴を有しているのです。RCではこの学習しない隠れ層を「レザバー層」と呼びます。
一般的なニューラルネットワークと比べると、RCは学習速度が上がりますが、精度は落ちます。そこで、私はレザバー層を固定したまま予測精度を上げる方法を探し、脳の神経修飾物質にたどり着きました。たとえばドーパミンは、特殊な出来事が起きた時に生成され、脳の一部を活性化させて注意機能を高めると考えられています。
この働きを模倣し、入力信号およびレザバー層からの出力に依存してレザバー層の活性度を多様に制御する「自己変調機構」を開発しました。本来固定されているレザバー層の活性度に新たな制御を加えることで、従来のRCよりも極めて高い時系列予測性能を持つ「SM-RC(Self-modulated RC)」へと進化させたのです。
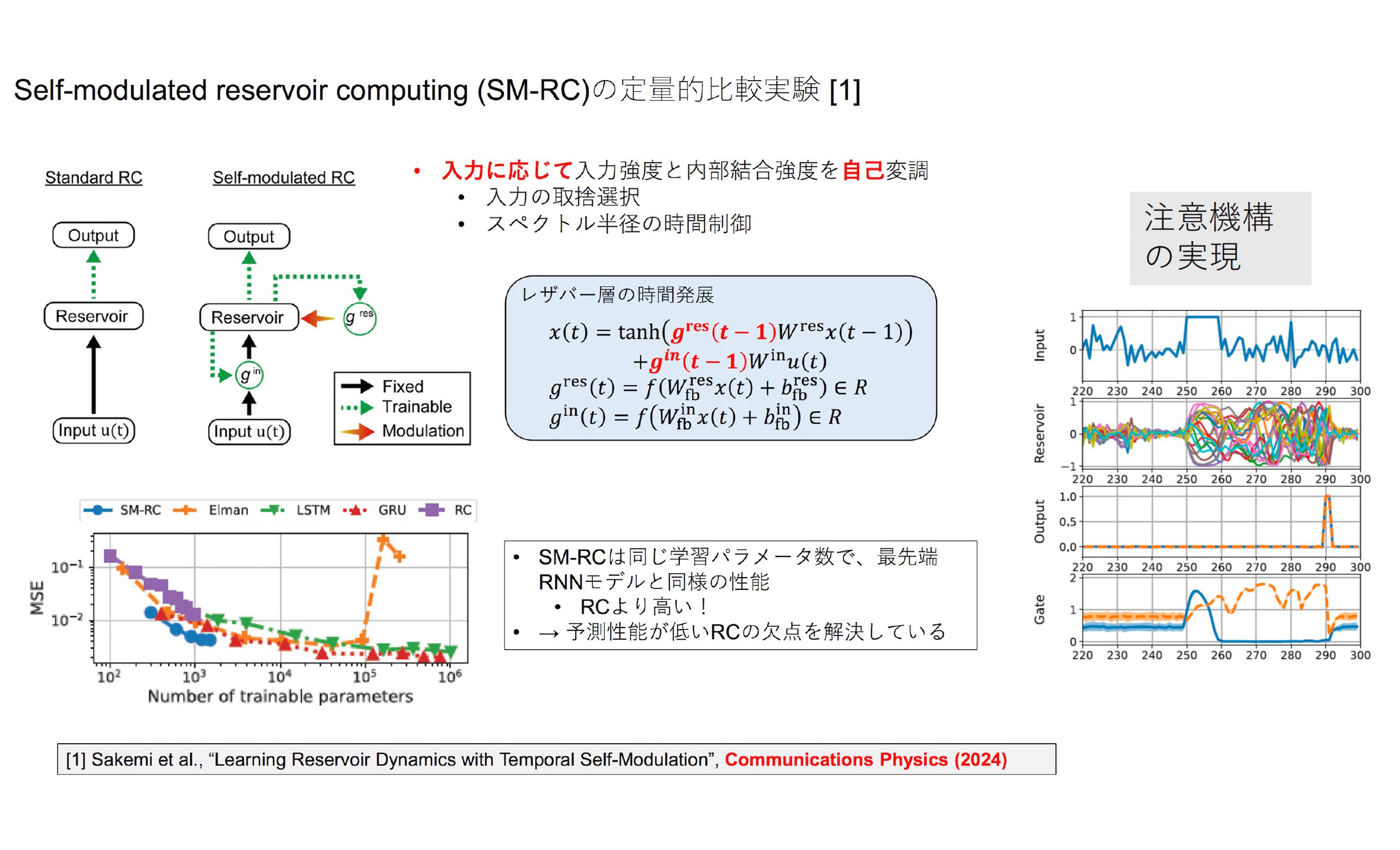 自己変調機能の開発と導入により、RCにおける注意機構を世界で初めて実現し、学習精度を実用化レベルに向上させた
自己変調機能の開発と導入により、RCにおける注意機構を世界で初めて実現し、学習精度を実用化レベルに向上させた本研究ではSM-RCに加えて、スパイキングニューラルネットワーク(SNN)のハードウェア化も進めました。SNNとは、生体ニューロンで観測される発火(スパイク)現象を、時間に依存する微分方程式系で再現するモデルです。情報伝達が2値のスパイクとなるため、高い電力効率が実現すると考えられています。
ところが開発したSNNのハードウェアシミュレーションの結果を見ると、想定していたほどの電力効率が得られませんでした。原因は、ニューロンの発火頻度の高さです。
現在のSNNをふくめたニューラルネットワークは高い発火頻度で動作しています。一方で、生体ニューロンの発火頻度は非常に低く、さらに状況に応じてコントロールされていると考えられています。その特性をモデルに取り入れることで、学習性能を維持したまま発火を抑える「正則化」を編み出しました。
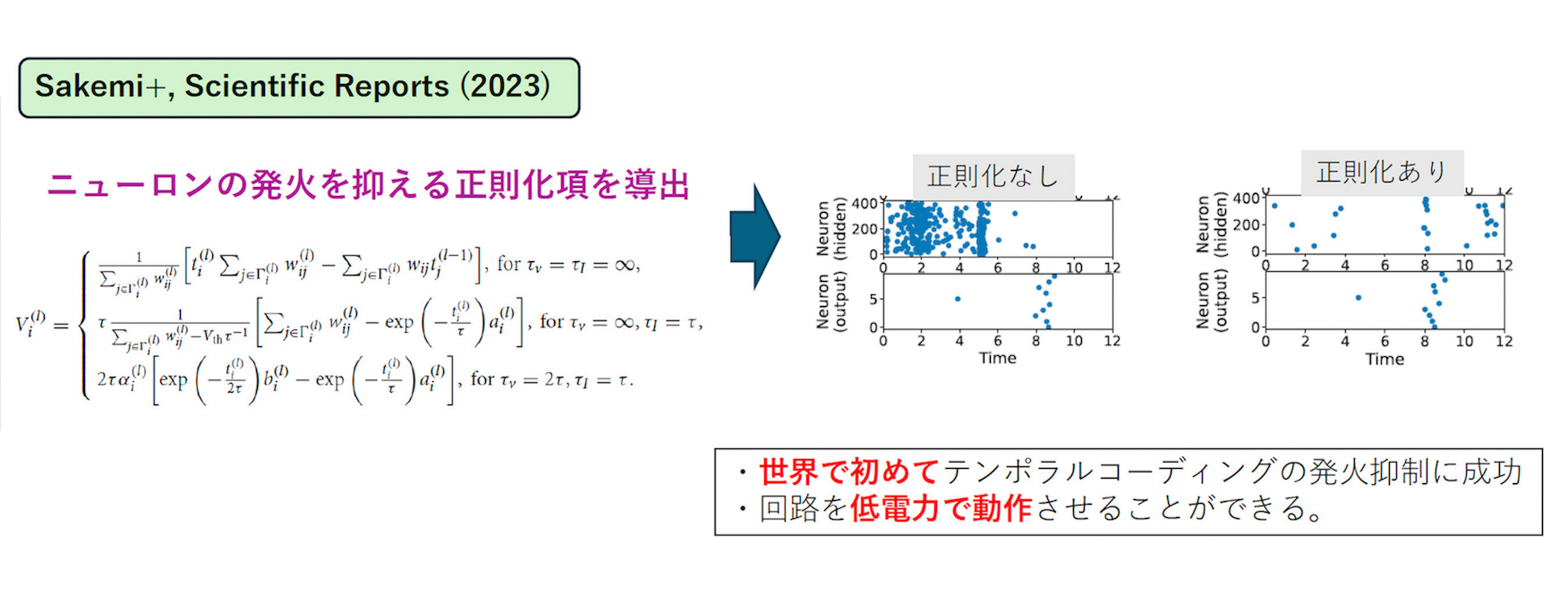 400個の人工ニューロンの発火状態。正則化によって、出力を維持したまま、発火(青い点)を約10分の1に低減した
400個の人工ニューロンの発火状態。正則化によって、出力を維持したまま、発火(青い点)を約10分の1に低減したただし、ここまでお話ししたことは、あくまでも「仮説」です。実際にハードウェア作って動かしてみるまでは、どうなるかわかりません。