今回は、前回の復習を兼ねて「なぜ音源分離が必要なのか」という方向からご説明します。音源分離というと、どのようなイメージをお持ちですか。

大規模な自然災害が発生したとき、被災者を探知する重要な手がかりとして、音データが注目されています。しかし、被災地にはさまざまな騒音があるため、充分な効力を発揮できているとは言えません。
前回は、音源分離によって騒音から被災者の声を抽出するご研究の概要をお話しいただきました。インタビュー第2回では、音原分離を可能にするアルゴリズムの詳細について、より詳しくお聞きします。
今回は、前回の復習を兼ねて「なぜ音源分離が必要なのか」という方向からご説明します。音源分離というと、どのようなイメージをお持ちですか。
典型的な音源分離の実験方法ですね。その場合、マイクの位置が明確であり、音源の種類も判明しています。
私達の研究対象は、ブラインド音源分離(blind source separation:BSS)です。ブラインドとは「見えない、知らない」という意味です。音の種類や数、マイクの位置関係がわからない状態で音源分離を実現します。
実は、私達は無意識のうちにこれを行っています。たとえば、昼休みに教室で、生徒達が大きな声で話しているとします。その喧噪から、自分の噂話だけは自然と耳に入ってきた、という経験がおありではないでしょうか。人間には「自分の聞きたい音」だけを聞き取る選択的聴取能力があるのです。
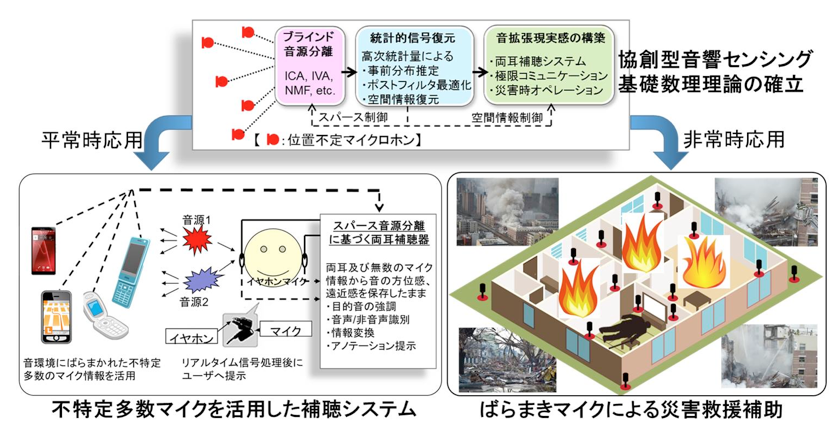 分散センサによる協創型音響センシングとその応用例
分散センサによる協創型音響センシングとその応用例下の図をご覧ください。男性の声をS1、女性の声をS2、混ざり合った信号をx1、x2とし、2つの音声がどのように混ざったのかを示す情報をHとします。
x1とx2から、S1・S2を抽出するためには、Hの情報が不可欠です。しかしHの情報を利用できないとき、私たちは2つのことを同時に推定しています。第一に、統計的に独立している音源の分類問題。第二に、各音源が属する確率分布の問題です。
これを閉形式で解く方法は、存在しません。しかし解けないことには、永遠にブラインド音源分離の進歩がないことも、また事実でした。
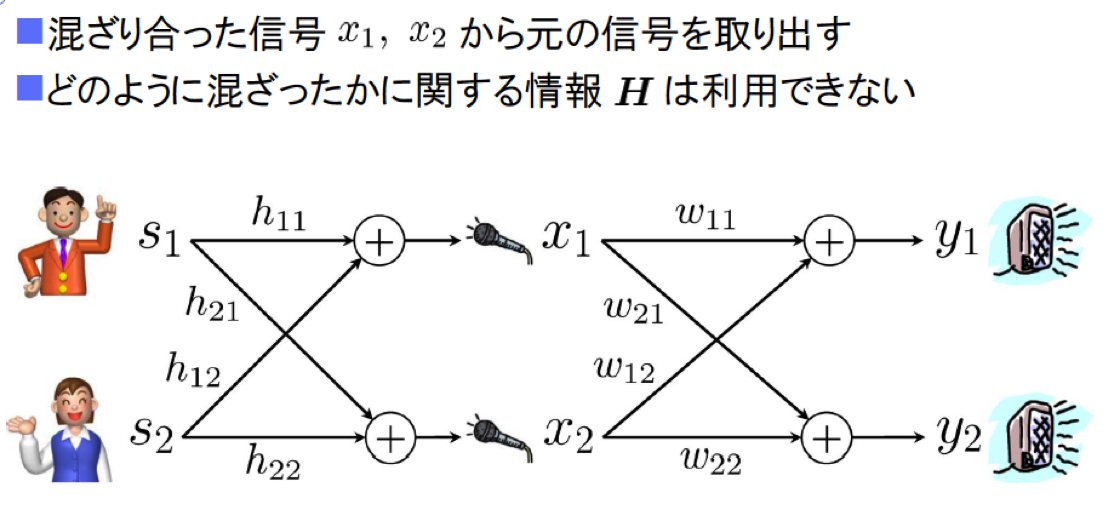 音源分離の略式図
音源分離の略式図