主な研究テーマは、音の発信地点、音をとりまく環境から受ける影響について着目した、情報処理です。特に「音源分離」という数理工学理論を、機械学習システムによって制御することで、人間の音処理能力の拡張を目指しています。
 音源分離を用いて人間の音処理能力を拡張すると語る猿渡先生
音源分離を用いて人間の音処理能力を拡張すると語る猿渡先生

東日本大震災や熊本地震など、大規模な自然災害が多発するなか、近年では、被災者を探知する重要な手がかりとして、音データが注目されています。被災者が発する音声を認識できれば、火災や倒壊する建物内など、救助隊が近寄れない場所でも被災者の存在を確認することができ、迅速な救助に繋がるからです。しかし、騒音によって被災者の声がかき消されてしまうため、災害時の音データは十分な効力を発揮できていないのが現状です。今回は、AIを用いた音声の解析方法について、東京大学大学院情報理工学系研究科システム情報学専攻の猿渡洋教授に、お話を伺いました。
主な研究テーマは、音の発信地点、音をとりまく環境から受ける影響について着目した、情報処理です。特に「音源分離」という数理工学理論を、機械学習システムによって制御することで、人間の音処理能力の拡張を目指しています。
音源分離を用いて人間の音処理能力を拡張すると語る猿渡先生目標とする音と、それ以外の雑音を分離することです。
たとえば、耳が聞こえづらく、補聴器をつけている人が、雑音が大きい場所で人と会話するとしましょう。通常の補聴器であれば雑音も拾ってしまい、人の声だけを聞き分けることは困難です。そこで、話し手のすぐ近くにマイクを設置すれば、聞き手の耳だけにマイクがあるよりも、さらに音を拾いやすくなります。このように、より円滑なコミュニケーションのサポートができるのです。
これは、災害現場においても応用できます。
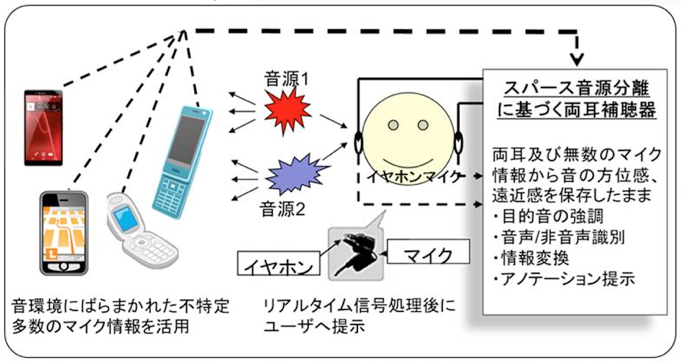 特定多数のマイクを活用した補聴システム
特定多数のマイクを活用した補聴システム