

- 2011年3月
- 自治医科大学 医学部 卒業
- 2011年4月
- 山口県の離島、山間部における僻地診療に従事
- 2020年12月
- 自治医科大学 大学院 博士(医学)取得
- 2020年3月
- 京都大学 大学院 医学研究科 社会健康医学系専攻 専門職学位課程 修了
- 2020年4月
- 福島県立医科大学 臨床研究イノベーションセンター 助教
- 2022年4月
- 京都大学 大学院 医学研究科・社会健康医学系専攻・薬剤疫学分野 特定助教
僻地勤務を通じて、人の健康は医療だけでは作れないことに気付いた
出身大学である自治医科大学は、僻地でも活躍できる総合医の養成に力を入れており、私も研修後は離島や山間部で「地域のお医者さん」として10年近く勤務しました。医療資源の乏しい僻地でできる医療行為には限界があり、治療よりも、診断や管理(糖尿病や高血圧など、治らない疾患を適切にマネージメントすることで重篤化を防ぐプロセス)に重点を置かざるを得ませんでした。
制約のある環境で様々なケースに対応するうち、医療技術の高さや処方薬の正しさよりも、患者さん自身の生き方や社会的背景のほうが、本人の健康を大きく左右する要因になっているのではという事に気付かされました。
医療の最終的な目的は「本人が幸せに生きること」ですが、治療だけがその手段ではありません。私は「地域のお医者さん」としては、患者さん一人ひとりと向き合ってきましたが、対象を集団として俯瞰すると、健康につながる普遍的な因子を知ることができるのではないかということにも思い至りました。例えば「独居か家族がいるかで、同じ病気でも進行速度や症状が異なる」という傾向が見えたとき、それが事実なのか、事実ならばどうすれば現状を良い方向へと変えられるのか、変えたときにその患者さんの生活はどう改善されるのか。それらを明らかにしたいと思うようになりました。そこで僻地勤務を終えたあと、大学院で疫学を専攻し、集団の見方や評価方法を専門的に学ぶことにしました。
 大学院では、自分が抽象的な概念としか思っていなかった仮説を、具体的な研究の対象にできることが新鮮で面白かった。研究によって「なぜそうなっているのか」を少しでも解明できることが一番の喜び
大学院では、自分が抽象的な概念としか思っていなかった仮説を、具体的な研究の対象にできることが新鮮で面白かった。研究によって「なぜそうなっているのか」を少しでも解明できることが一番の喜び臨床研究の可能性を広げる「医療ビッグデータ」
臨床研究は、大まかに介入研究と観察研究に分類されます。介入研究の代表例は、新薬開発などの際に行われるランダム化比較試験(Randomized Controlled Trial、RCT)です。これは対象者の集団をランダムに二分して、片方の集団にのみ新しい治療を行い、他方の集団と比較するものです。
観察研究はこれとは全く異なり、対象者への介入はせず、自然に発生する様々な実態データに対して、工夫を凝らして観察することで仮説を検証します。特に、人の考え方、持って生まれた性質、害になること等に対して実際に介入することは倫理的に難しいですから、人の健康に関わる複雑な問題を検討するためには、介入研究だけでなく観察研究が必要です。
最近では、膨大なデータ量を持つ「医療ビッグデータ」(主に電子カルテに入力された医療行為の記録)が身近になったことで、観察研究の可能性が飛躍的に拡大しています。今まで不可能と考えられていた、介入研究の結果を観察研究で再現することができるようになりつつあり、さらに、介入研究に観察研究を組み合わせることで、新たな領域を開拓する方向性も期待されています。医学におけるデータサイエンスは、臨床研究の可能性を広げる手段としても今後もさらに注目を集めていくはずです。
無駄なくデータを補える、データ融合の新手法を開発
膨大な情報量を誇る医療ビッグデータですが、電子カルテの性格上、含まれる情報の種類は限られています。本研究では、医療ビッグデータを異なる医療データベースと融合する新たな手法を開発して、データベース活用の幅を広げることを目指しています。これが実現すれば、新しい知見を導くことも期待できます。
医療データベースどうしは通常、性別や年齢、服用した薬などの膨大な共通部分を持つ相補的な関係にあります。このようなデータベースAとデータベースBを融合する場合を考えましょう。
従来のデータ統合は個人の照合が必要であり、それがボトルネックになっていました。しかも、片方のデータベースにしか情報がない人のデータは使えないため、統合の際には多くの情報を捨てざるを得ません。
そこで本研究では、個人照合が不要となる、新しいデータ融合手法を開発しました。共通データ以外のデータを「特異的データ」とすると、データベースAは「共通データ+特異的データA」、データベースBは「共通データ+特異的データB」からなると言えます。機械学習法で共通データから特異的データAを導き出す計算式「モデルA」を作り、データベースBに適用すれば、データベースBで欠測していた部分(データベースAにはあり、Bにはない項目)を仮想的に埋められます。これによってデータを無駄にせず、より大きなデータベースを作れると考えました。
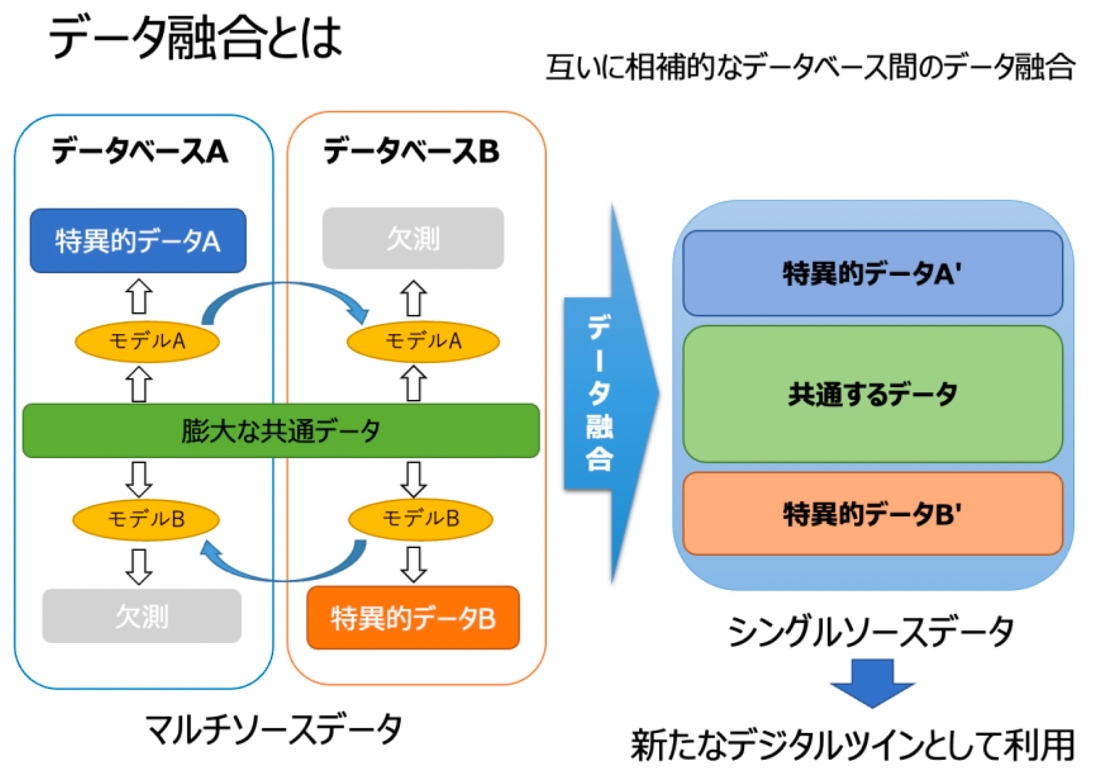 膨大な共通データを利用して、データベースどうしの欠測部分を補う
膨大な共通データを利用して、データベースどうしの欠測部分を補う2つのデータベースからは、欠測部分の正しい推定ができない
新しいデータ融合手法の妥当性を確かめるため、あるデータベースを人工的に2つに分けて一部を相補的に欠測させ、それらを融合して元のデータベースに戻す検証を行いました。ところがやってみると、まったく戻らないのです。
試行錯誤の末、2つのデータベースでは一部の特異的データ間の関係性が学習できないことに気づきました。そこでデータベースを3分割し、循環関係になるように相補的な欠測を作ることで、ようやく復元に成功しました。データ融合の大前提として、相補的な欠測のデータ間の関係性をデータベースのどこかでは観測できる必要があることが分かったのです。
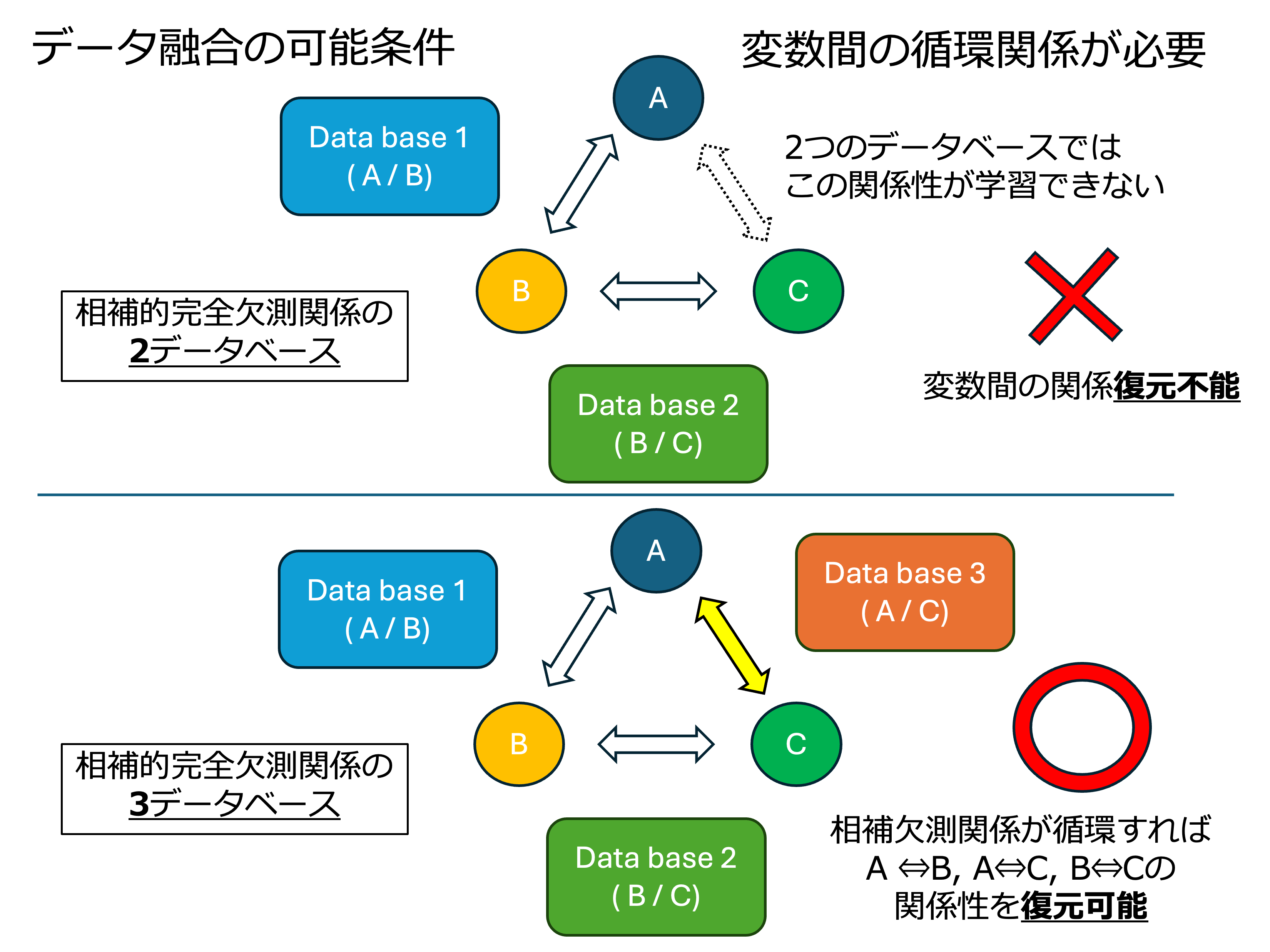 データベース1はデータ「A」、「B」を含み、データベース2はデータ「B」、「C」を含む。AとCの関係性をも学習できなければ、A、B、Cすべての因果関係が成立する構造に戻せない
データベース1はデータ「A」、「B」を含み、データベース2はデータ「B」、「C」を含む。AとCの関係性をも学習できなければ、A、B、Cすべての因果関係が成立する構造に戻せない